

Overview
This article introduces CASTER (Context-Aware Strategy for Task Efficient Routing), a lightweight routing approach for dynamic model selection in graph-based MAS.
Paper link here 👉 Liu, S., Yuan, X., Chen, T., Zhan, Z., Han, Z., Zheng, D., Zhang, W., & Cao, S. (2026). CASTER: Breaking the cost-performance barrier in multi-agent orchestration via context-aware strategy for task efficient routing. https://arxiv.org/pdf/2601.19793[1]
Across Software Engineering, Data Analysis, Scientific Discovery, and Cybersecurity tasks, LLM-as-a-Judge evaluations show that CASTER cuts inference costs by up to 72.4% compared to strong-model baselines, while matching their success rates and consistently outperforming heuristic routing and FrugalGPT.
The Token Tax Problem Holding Agentic AI Back
In practical AI deployments, teams run into a genuine trade-off. At one end are proprietary frontier models, including the GPT family and Claude 3.5 Sonnet. These models provide the reasoning strength needed for demanding tasks like code generation or security analysis. At the other end is cost. Their pricing sits far above open-weights models or lightweight “Flash” variants, which makes them hard to justify in automated workflows that run often and at scale.
This tension intensifies in Multi-Agent Systems (MAS). An agentic workflow is not a single exchange. It repeats. It corrects itself. It calls tools. It plans across multiple steps. In real terms, a single task can trigger many model calls. A software engineering agent, for example, may need anywhere from 10 to 50 inference steps to fix a single bug.
When each of those steps defaults to a strong model, the “Token Tax” rises fast. Costs stack up across iterations, and workflows that look acceptable in theory fail basic cost checks in production. The alternative is not much better. Forcing a weaker model across the workflow often creates failure loops, where the agent:
- Attempts the task without enough reasoning capacity
- Produces an incorrect or incomplete result
- Retries again and again without moving forward
In these cases, tokens are still spent, but the system never settles on a working solution - wasting time and resource.
Our work introduces CASTER, a framework intended to move past this trade-off. Instead of treating model choice as a fixed setting, CASTER treats it as a decision that adjusts to the task in front of it. By learning when stronger models are needed and when cheaper ones are sufficient, the system reaches a Pareto-superior result, lower costs without reducing success rates, and in some cases improving them.
In deployed AI systems, practitioners face a clear split. Proprietary frontier models, such as GPT-4o or Claude 3.5 Sonnet, offer the reasoning depth required for complex tasks like code generation and security analysis. Their cost structure, often far higher than open-weights models or “Flash” variants, makes them impractical for high-frequency automated workflows.
This issue becomes sharper in Multi-Agent Systems (MAS). Unlike a single-turn chatbot, an agentic workflow includes loops, self-correction, tool calls, and multi-turn planning. A software engineering agent may require 10 to 50 inference steps to resolve a single bug.
If every step defaults to a strong model, the Token Tax builds quickly, and many use cases stop making financial sense. Pushing everything through a weaker model leads to a different failure pattern, repeated attempts that burn tokens without reaching the goal.
Our research presents CASTER as a way through this constraint. By treating model selection as a learnable decision rather than a static configuration, we achieve a Pareto-superior outcome, significantly lower costs with equal or better success rates.
Deconstructing the Cost Reduction
We achieved a 72.4% cost drop in Software Engineering workloads using OpenAI models. That number tends to raise eyebrows. How does this happen without hurting output quality? The explanation sits in waste built into routing.
Our tests showed that a large share of agent steps are routing-compatible. This means they can run well on cheaper models. Pinpointing exactly which steps qualify remains hard to judge reliably.
The Failure of Static and Cascade Strategies
Most optimisation approaches land in one of two buckets, and both struggle with agentic workflows:
Static allocation. Teams default to expensive models to cover worst-case complexity. Even when 90% of the workload is lightweight, every step still pays the full cost of the strong model.
Cascading approaches (for example, FrugalGPT). The system starts with a cheap model and escalates only after failure. This works for basic Q&A, but agents behave differently. Our tests exposed two problems:
- Quality dilution. A weaker model may not fail outright. It produces code that looks reasonable but is wrong, sending the agent down a dead end.
- Context pollution. When a weak model misses the mark, it often leaves behind noisy or incorrect context. Even if the system switches to a larger model, that polluted context slows correction, wastes steps, and can cost more than starting with the strong model.
How CASTER Spots Complexity Before It Spends Lots on Compute
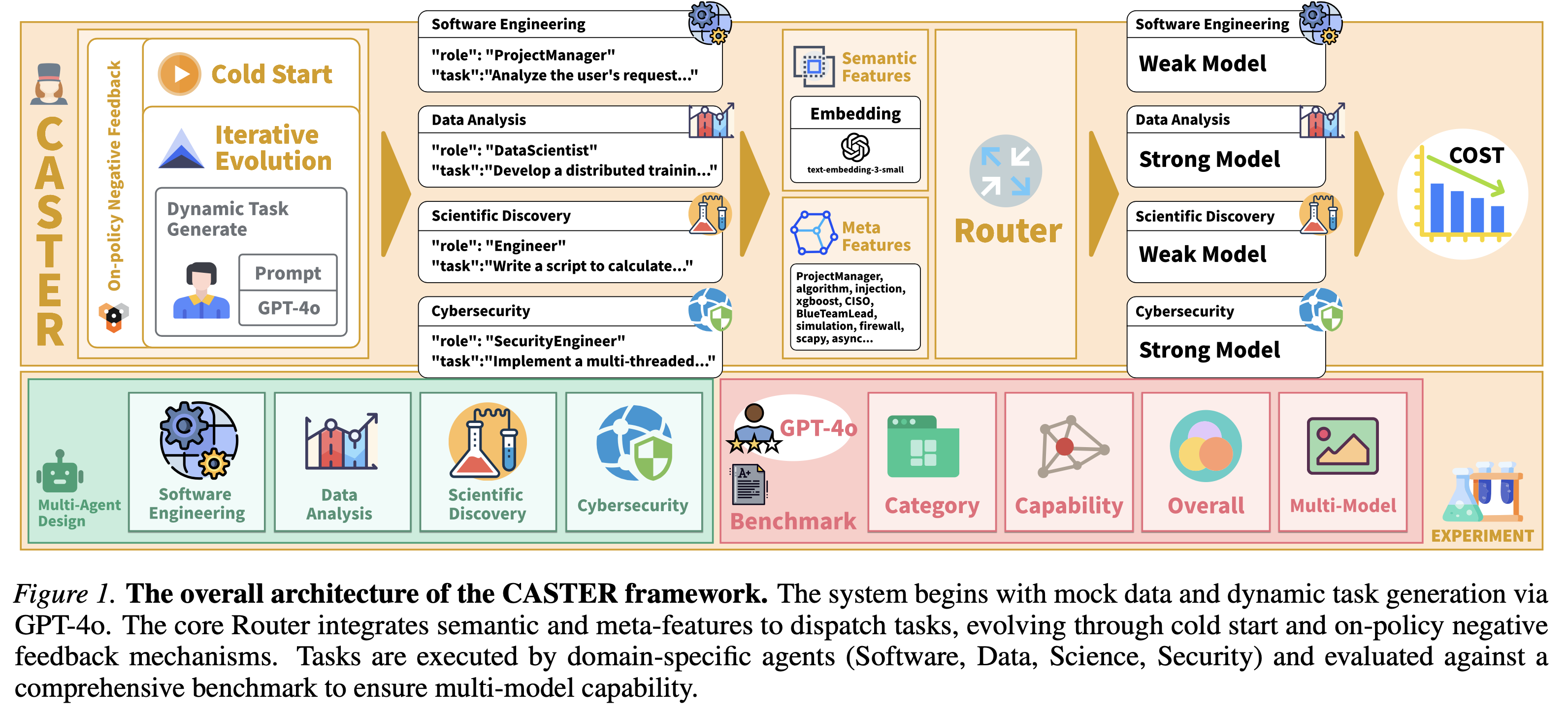
CASTER uses a lightweight neural router to decide whether a strong model is needed before a step runs. It reads more than the user prompt. It looks at the agent’s current state, for example whether it is debugging an error or just formatting data. The network combines two inputs: semantic embeddings and simple meta-features, including the agent’s role and the type of task it is handling.
In Software Engineering tests, the router correctly flagged around 70–80% of sub-tasks as safe for a cheaper model, with near-100% success. The expensive model was held back and used only where it added value, mainly architectural reasoning and complex logic work.
Crucially, training and test data were kept separate to avoid leakage. We started with a cold start using a small set of representative tasks, then moved to iterative evolution, where the router learned from offline traces and live feedback. This makes the 72.4% cost saving a result of real generalisation. In production systems, the line is less strict. Learning by doing can push performance even further over time.
The Efficiency Mechanism for Pareto-Frontier Performance
It’s easy to assume that moving 70% of calls to a cheaper model would hurt success rates. That drop never appeared. The reason sits in what we call cognitive rightsizing.
Strong agents don’t need top-tier reasoning at every step. A large share of tokens goes on routine work, including:
- Log parsing
- Data formatting
- Basic syntactic completion
Using a frontier model for these steps is simply paying a safety tax for reassurance, with no added value.
CASTER removes that tax and acts as a strict quality gatekeeper. Unlike cascade approaches that let weak models attempt tasks and fail, CASTER blocks weak models from tasks they are predicted to mishandle. Complex reasoning always goes to the strong model. Mechanical work is pushed elsewhere. This keeps the system on the Pareto frontier, extracting the most reasoning value per dollar spent.
Comparable Outcomes Across Claude, Gemini, DeepSeek and Qwen
To address vendor lock-in worries, we extended our benchmarks across Claude (Anthropic), Gemini (Google), DeepSeek, and Qwen.
The results exposed economic patterns. For providers with sharp price gaps between Pro and Flash models, including Anthropic and OpenAI, savings were substantial, averaging 52.01% and reaching 72.4%. By contrast, DeepSeek, where the pricing gap stays tight, delivered smaller gains.
We also saw occasional cost inversion, where the router or weak model cost more than the strong baseline because extra tokens were spent inside correction loops.
This insight is vital. Orchestration strategies must be coupled with pricing strategy. CASTER's model-agnostic architecture allows enterprises to swap backends without rewriting routing logic.
Implications for Production Environments
For engineers planning to apply similar ideas in production, our work points to three practical architectural considerations.
A. Latency vs. Throughput
In real-time systems, such as customer support agents, latency matters most. Sequential cascades, FrugalGPT-style, add the weak model’s delay whenever that model fails. In our experiments, latency was not the main metric, but the added overhead from CASTER mostly came from calling an OpenAI embedding model to judge task difficulty.
In production settings, this can be reduced by running a local, low-latency embedding model for fast vectorisation. By letting CASTER choose the right model upfront, we cut time to result. In our Data Analysis benchmarks, avoiding repeated retry loops from weak models actually improved overall wall-clock time on harder tasks.
B. Handling Multi-Modal Complexity
Real-world agents do more than read and write text. In our Data domain, agents had to generate Python code to produce visual outputs like plots and charts. We saw that weaker models often stumble on the multimodal detail of checking whether a plot actually matches the data.
We used GPT-4o as a judge in the evaluation pipeline, relying on its multimodal strengths to validate outputs. In production, this points to a clear need for modality-aware routing.
When a task involves visual checks or image generation, the router should strongly favour multimodal-capable Strong models, since text-only Weak models fail far more often in these cases.
C. Offline-to-Online Refinement
How do you deploy this without labelled data? We propose a Cold Start approach:
- Mock training: use synthetic data, or a small set of Strong model traces, to train an initial router.
- Online iteration: as the system runs, log successful and failed paths to refine the router over time.
Our results show that even a router trained only on synthetic data beats static baselines, but the online refinement step is what lifts cost savings from roughly 40% to more than 70%.
The Future is Built to Adapt
The phase of picking a single “default model” is coming to an end. As systems move towards autonomous workflows, task complexity shifts from fixed to fluid and hard to predict.
CASTER shows that teams no longer have to choose between the raw capability of frontier models and the cost efficiency of lighter ones. With context-aware routing in place, access to high-intelligence workflows becomes far broader.
The 72.4% reduction we measured is not a hard limit but an early signal.